Do you ever hear about Web crawlers, if yes then What is a web crawler? and what it works, how much it is important in the world of the internet. Actually, When we search for any information through search engines like Google or Bing it presents a big list of related information before us as URLs. Did you ever think about how a search engine does this, from where the search engine gathers those huge information? Here really, the web crawlers come into existence.
Web crawler what is it?
“Web crawlers” often also called digital spiders or bots, are designed to search for and collect new data from websites traveling the World Wide Web. It is the most important part of any search engine which enables the search engine to properly index web pages in SERPs.

Actually, it is a trained bot that goes around the internet collecting information about websites. You may think of it also as like a robot that travels the website with the intensity to gather data about different websites. You can think of It like a virtual spider, that always wondering out newly published content and collecting information, and works hard for search engines.
How Does the Web Crawler Work?
Typically, web crawlers begin by crawling a list of recognized URLs. They then follow other URLs or hyperlinks on that page and continue to collect data and search for those web pages that can be indexed. This process goes on continuously. Usually, they keep searching for new pages on the Internet as well as looking for these pages in which any changes have been made.
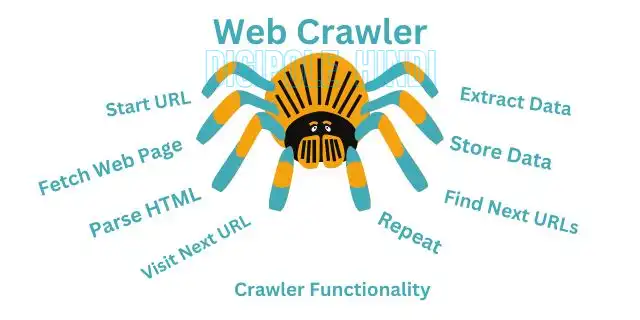
Web crawlers are working using bots that are pre-designed for the purposes of collecting the necessary data insense of indexing their URLs for search engines. In fact, it is a software program that is instructed by an algorithm.
Although, there is another algorithm that works simultaneously with the web crawler, which is called a web scraper, that downloads the necessary information from a website.
However, despite of the similarities between web scraping and web crawling, they are actually perform a different task. Scraping is accountable to parse and extract data from a website, while web crawling is responsible to search for URLs. Further in this article, we will also try to understand the difference between web scraping and web crawling.
What is web scraping?
Web scraping is an auto process to collect a large amount of information from a website. Among them, most of the scraping data are gathered in an unstructured format which is later converted into a structured form in a spreadsheet.
These scraping tools are basically a bot that is specially programmed to perform extract information from various websites. This tool is used for various purposes such as market research for businesses, governmental vigilance, etc.
Difference between web crawling and web scraping?
As I told before that, web crawlers are pre-design programs that fetch information and save them to show on search engine result pages in a sequence form.
On the other, Web scraping is happening when a bot downloads a piece of content on a website without any prior permission. These are often happen when intentionally inject a piece of content or code for spreading malicious on a website.
web scraper bots may disregard the robots.txt instructions, while on the other, web crawlers, will obey the search engine’s role, as it is controlled by the robots.txt file.
Different types of web crawlers
There are various types of crawlers are in existence and Each of them is designed to perform specific tasks or uses for specific applications. Although, Each crawler may be compared with its different parameters. Before knowing about the different types of web crawlers, it is important to know about their 3 main types:
- In-house web crawlers: It is developed by the company to fulfill a specific purpose, such as monitoring the activity of a project or website.
- Public web crawlers: These are publicly available on the Internet for free, and anyone can use them if they want. Googlebot, Bingbot etc. come under this category. It is generally used to collect and index data for search engines.
- Niche web crawlers: These are basically programmed to crawl websites with specific content. Such as job related websites, news websites and e-commerce sites etc.
Now let’s look at the different types of crawlers with their purposes:
- Deep Web Crawlers
- vertical crawlers
- Archival Crawlers
- link checker
- Distributed Crawlers etc.

web crawler example
Here are given some commonly used web crawler’s examples that are belong to different search engines:
- Googlebot
- Bingbot
- Yahoo! Slurp
- YandexBot
- DuckDuckBot
- ExaBot
How do web crawlers affect SEO?
As we know, SEO is the abbreviation of search engine optimization, which plays a big role in search indexing so that a website shows up higher on the search engine results page. It works with understanding the meta description, H1- H2 Heading, and content relevancy of a web page fetching through a spider bot. In simple terms, a website most probably index to shown higher in search result if crawler understand the webpage better and comply its roles properly without any resistance by robots.txt
But when spider bots can’t able crawl well a website due to the blocked through robots.txt file, it doesn’t index, and as a result, it won’t be shown in search results. So, as a website owner, it is most important to set properly the robots.txt file so that it gets more organic traffic from search results.
What is the main purpose of a web crawler?
Web crawlers are basically, designed to explore information by traveling through out websites. In this way, they find out the information that can be indexed for search engines to display in search results.
Are web crawlers robots?
From the perspective of software technology, both crawlers and robots are similar. Both are performed in auto-process ways and both they are programmed to collect and analyze data. So, looking at their work processing and their purposes it can be recognized that both are robots.
Why is a web crawler called a spider?
“Web crawler” which is also known as spider, because it act like a spider. When a spider weaves its web it start with a string first as a base. After that following this string it makes the full web. Similarly a web crawler is also works following this process. It also starts crawling first with a base link (URL) and moves forward to complete its task.
- What is a Compiler?Difference between Compiler/Interpreter - November 27, 2023
- What is system software? How it works and its types - November 26, 2023
- Why website does not rank despite good SEO? - November 25, 2023